
Boosting algorithms. The very concept of the word boosting emerged from the field of machine learning.
Unlike many machine learning models, they all focus on providing high-quality prediction based on one single model. But with boosting algorithms, such predictions can be improved by training sequences of weak models.
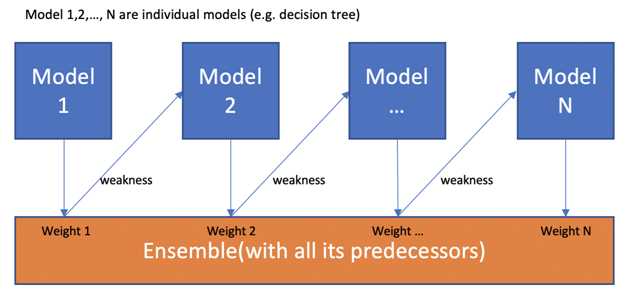
Image source: International Journal of Advanced Science and Technology
Boosting algorithms are accountable for improving the accuracy of the predicted values. It helps in transforming weak learners into active learners. These are some of the machine learning algorithms methods used to detect weak rules. At the end of the boosting process, the combination of all the weak rules transforms into a strong rule and thus proves to be highly efficient.
Let’s quote an example here:
Imagine you’ve built a linear regression model that will give you 77 percent accuracy on the validation dataset. Now, perhaps you wish to expand this portfolio by building another model, k-Nearest Neighbor (KNN), and decision tree models on the same dataset. These models would ideally give you an accuracy of 89 and 62 percent on the same validation dataset.
It is evident for all these models to give different accuracy percentage. The linear regression model will try to capture the linear relationship in the data while the decision tree model might eventually try to capture non-linear relationships in the data.
But what if we combine all three models for final predictions instead of relying on one single model?
This is where the term ensemble learning comes into the picture. And boosting is a technique that uses the concept of ensemble learning. As mentioned earlier, boosting algorithms helps in combining multiple simple models i.e. weak learners in generating the final output.
Let us further explore four major boosting algorithms:
1.Gradient Boosting Machine (GBM)
The GBM collects predictions made from multiple decision trees to generate the final output or prediction. Not to mention, most of the weak learners used in gradient boosting machines are all decision trees.
Here’s a question, if the same algorithm is used, how using a hundred-decision tree is better than using a single decision tree? How is it even possible for different decision trees to capture different information from the same data?
A simple answer to this is,
The nodes present in every decision tree ensure to take a different subset of features and chose the best split. This means all decision trees are not the same thus making it possible for them to capture different information from the same data.
Every tree ensures to have an account of the mistake or error the previous tree has made. Therefore, every successive decision tree is build based upon the errors of the previous tree. This is how the process of gradient boosting machine learning algorithm are built.
2. Extreme Gradient Boosting Machine (XGBM)
Extreme Gradient Boosting or XGBoost is an improved version of GBM.
XGBoost is another popular boosting algorithm renowned for correcting the errors of the previous trees. The XGBoost follows the same working principle as GBM.
Some interesting features to note why it is better than GBM:
- XGBoost consists of varied regularization techniques leading to better performance and helps reduce overfitting.
- You can set the hyperparameters of the XGBoost algorithm and choose the regularization technique.
- Also, XGBM helps in implementing a parallel preprocessing at node levels making the process much more efficient than GBM.
An added advantage, if you’re using this algorithm, you need not worry about representing the missing values in your dataset since the XGBM can handle missing values on its own. During the ongoing training process, the model learns where the missing values exactly need to be (either on the right node or the left node).
3. CatBoost
As the name suggests “CatBoost” is an open-source machine learning library. It is another boosting algorithm accountable for handling categorical variables in data. Further on, these categorical variables are converted to numerical values as a part of preprocessing.
CatBoost algorithms possess the capability of internally managing variables in the data. Thus, these variables are changed into numerical values with the help of statistics combination features.
Another major reason why CatBoost machine learning algorithms have been widely used. One of the major reason is because it works perfectly great with a default set of hyperparameters. Thus, being a user, you do not need to waste time tuning these hyperparameters.
4. LightGBM
LightGBM is known for its speed and efficiency.
This boosting algorithm is capable of easily handling large amounts of data. You need to keep in mind that LightGBM does not work well when there are considerably fewer data points.
This occurs because LightGBM has a leaf-wise growth and not level-wise. Thus, after every split, the next split takes place on the leaf node with a higher delta loss.
Boosting algorithms altogether represent a different level of machine learning perspective while transforming weak models into strong models.






")



