
It was estimated that over 2.14 billion people patronized e-Commerce stores last year. This provided a huge opportunity for companies to sell in a booming market while providing customer satisfaction.
And most of what e-Commerce brands are enjoying today is from the abundance of data and the wise application of relevant ones to make important business decisions.
Businesses can protect themselves; monitor the market and other brands while seeing what their consumers want just by collecting the right data.
Many businesses only know about web scraping when harvesting the data they need to grow their company. However, it is time to pay more attention to web crawling, which defines how the internet works aside from helping to make data available in large quantities.
What Is A Web Crawler?
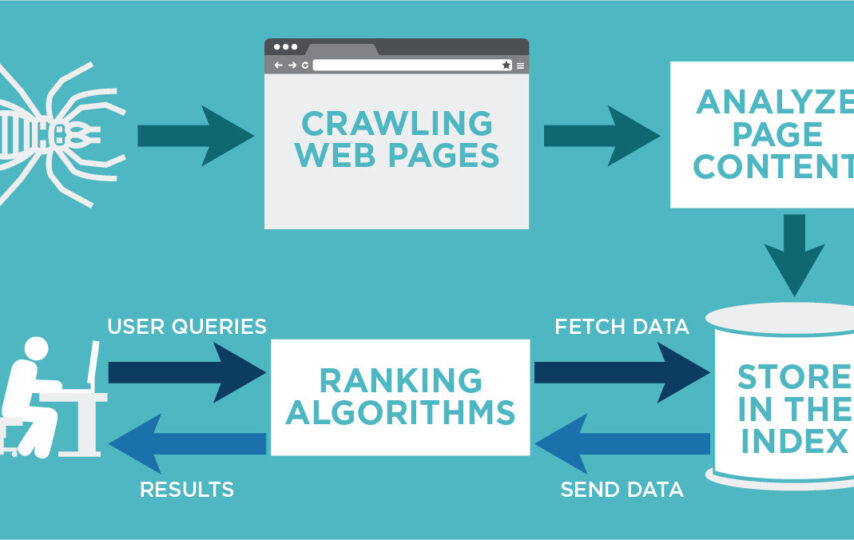
A web crawler can be defined as a tool or program that works automatically to systematically search through different pages and websites and collect and store the information they contain.
These tools start by interacting with a URL or few known URLS and go from there to find and interact with other embedded URLs while collecting and storing data as they go.
Doing this systematically and methodically helps collect and keep URLs for immediate or future use while indexing the different websites on the internet.
So that, on the one hand, it gives businesses the chance to access different content on the internet. On the other hand, it makes the internet more organized and easier to access information. Overall, you can read the article here and see that crawlers have many features, unique peculiarities, and benefits.
What Are The Types Of Web Crawlers?
The definition above should help you conceptualize what is a web crawler. Yet there are different types available for people according to their needs and goals.
Below are some of the major types of web crawlers:
- Focused Web Crawler
This type of crawler is also known as a Topic Crawler as it often works to ensure that it only collects and stores information related to a specific issue or topic.
Rather than roam around the entire internet, the Focused Crawler ensures only to follow URLs and documents that are relevant to a given topic.
This way, you can collect a huge amount of data while saving a great deal of time and resources as you do not need to go around the internet.
- Incremental Web Crawler
Most web spiders work by collecting new information and deleting the old one to create room for the newly harvested data.
This is unlike the Incremental Crawler that crawls and establishes data sources and collects new data. Still, instead of removing the old one, it simply refreshes the stored data in incremental order.
This way, some web pages are visited as often as they update their data, and fresh data is collected and used to refresh what has been stored.
Less valuable data can also be replaced with newer and more relevant data during this crawling.
Its major advantage is data enrichment, as it always refreshes what is in store. It also ensures only the most valuable data is supplied at the end.
- Distributed Web Crawler
Some web crawlers work to cover specific areas and topics, while others like the Distributed Web Crawler cover as many pages on the web as possible.
This crawler can easily handle communications and synchronize nodes to ensure that crawling is geographically distributed.
What you get at the end is a more robust representation of what is contained in the World Wide Web. A second benefit is that this crawler can be used with different crawling applications.
- Parallel Web Crawler
This type of crawler is only used in cases requiring more than one spider at once. A Parallel Crawler works with other Parallel Crawlers to create multiple crawling processes that quickly index websites and make data abundant in abundance.
The advantage is that data collection, storage, and indexing can be quickly achieved, and you can end up downloading a substantial quantity of relevant data in a reasonable amount of time.
What Are The Primary Differences Between The Types of Web Crawlers?
The key difference between all the above crawlers is how exactly they function. As one can see from above, the Focused Crawler only collects data related to a given topic. In contrast, the Incremental and Distributed Crawlers work to harvest and refresh data in increasing order and cover a wider network of the internet, respectively.
The Parallel Crawlers work together to perform the job faster and quicker, thereby yielding localized or geographically distributed data more efficiently.
What Value Can A Web Crawler Provide An Organization?
There are so many ways a web crawler can provide benefits and value to any organization. These values often depend on what the company is using and what it is being used to achieve.
For instance, Real Estate companies often use web crawling to ensure better search results and content organization on their websites.
It can be used to create catalogs for images and other information making it easier for buyers and potential buyers to navigate and find what they want.
This benefit is similar to what is obtainable in the automotive sector, where these tools are used to organize information that can help narrow down buying decisions and make buying a much easier and faster process.
Conclusion
Brands that know what is a web crawler also know exactly how to use it to their greatest advantages.
Not only does a web crawler help to organize the internet and websites, but it also helps businesses and internet users find what they are looking for very quickly.







")



